
This is the second post of a series of articles about how the several technologies conforming the New Gaia Architecture (NGA) fit together to speed the Web.
In the first chapter, we focused on performance and resource efficiency and we realised the potential conflict between the multi-page approach to web applications where each view is isolated in its own (no iframe) document and the need for keeping in memory all the essential logic & data to avoid unnecessary delays and meet the time constrains for an optimal user experience.
In this chapter I will explore web workers in its several flavours: dedicated workers, shared workers and service workers and how they can be combined to beat some of these delays. As a reminder, here is the breakdown from the previous episode:
- Navigate to a new document.
- Download resources (which includes the template).
- Set your environment up (include loading shared libraries).
- Query your API for the model.
- Combine the template with your model.
- Render the content.
Web Workers
Multithread programming has been available in browsers for years now but very few people realised about it. A Web Worker is a piece of JavaScript code running on its own global scope independently of the main thread. Actually, Web Workers API spawns an OS level thread when creating the Worker.
Does it mean I can run several JavaScript threads at the same time, modifying the DOM and accessing all my data in a concurrent environment? Well… yes and no. Yes, you can create concurrent code in JavaScript but no, you can not access non thread-safe APIs from Web Workers.
Attending to their life-cycle, Web Workers present themselves in three flavours:
- Dedicated workers are tied to the window that created them, so once the tab is gone, the worker is terminated.
- Shared workers, on the contrary, stay alive while other pages in the same origin remain open.
- Service workers are bound to the domain itself and they don’t depend on any client page. They start to run on specific events and end automatically once the event is handled.
The role of workers
How this workers can help reducing delay?
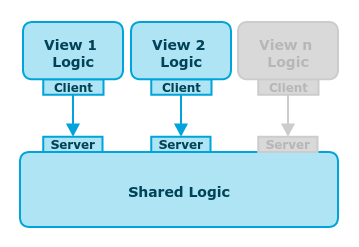
For starters, let’s focus on delay 3. In a single web application, business logic and core functionality are loaded once at initial set-up and they can be shared among different views until the application is closed. But in the new (old) NGA’s multi-page approach, navigating to another view would cause a new set-up per view. As shared workers survive page navigation, they can be used as containers for shared logic.
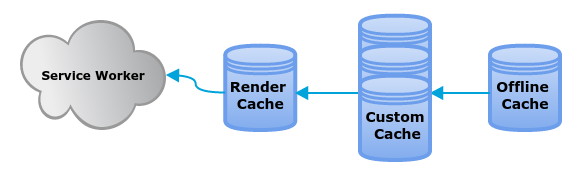
Now let’s move our attention to delays 2, 4 and 5. Delay 2 is about downloading resources from the Network. In a Firefox OS application, we have packaged apps which are actually zip files with all the contents for the application so there are no remote requests to download resources. But these packaged applications or the future pinned cache are very Firefox OS specific. They provide a rigid life-cycle for applications but what about the World Wide Web? Can we control this application life-cycle in some way? Yes. With Service Workers + Offline Caches.
One of the events that a Service Worker react to is an http request. They are able to intercept any request to the Network providing a custom response. In addition, they can use a special new type of database to store pairs of request and responses, i.e., the Cache API.

This can reduce all the Network delay enabling near-to-packaged-apps fetching speeds to standard web applications. Moreover, Service Workers enable custom life-cycles for installing, serving and updating resources.
Finally, let’s know more about delays 4 & 5, querying the model and combining into the template. A basic query to a remote or local API result in a set of records. This set is then transformed, filtered or aggregated and passed to the view logic to get the proper HTML representation. Offline caches could store the transformed dataset result of querying the model and avoiding delay 4 but, more radical, they could store the complete HTML textual representation for the already combined template to nullify delay 5, template combination. This is what we call the render store.
This combination of different caches lead to some cache hierarchy for offline content.
But the use of service workers does not come without cost. Some API are not accessible from Service Workers yet and the communication between contexts involve relevant penalties. Furthermore, these optimisations work when some content is already available and we still need to figure out how to speed the first-use case up.
Summarizing, dedicated workers can play any function in a real concurrent environment keeping constant hight frame-rates, shared workers can hold shared status surviving navigation and service workers, in addition to offline caches act as persistent caches avoiding network access and saving rendering time.
In the next chapter, I’ll explore prefetch, prerender and pinned cache to address the remaining delays and build a complete strategy for minimizing the effort of rendering views. Stay tuned!

3 comentarios en “Modern Mobile Web Development II: The Role of Workers and Offline Cache”